简介
当今,检索增强生成(RAG)已迅速成为在企业环境中部署大型语言模型(LLM)的标准架构模式。尽管基础模型拥有强大的推理能力,但它们也存在固有的局限性:它们受限于知识截止日期,并且无法访问专有或私有数据。RAG通过将概率生成建立在可验证的外部数据之上来解决这些问题,从而有效地减少了臆想现象的发生。
在深入学习检索增强生成之前,如果你是这个概念的新手,建议你先阅读一下我们的上下文工程入门指南,以了解相关的基础知识。
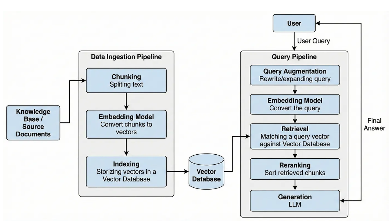
基本RAG架构
为了理解RAG的核心机制,我们可以考虑一个法庭内容的类比:
- LLM(法官):具备推理和解释能力,但知识仅限于一般知识。
- RAG系统(法院书记员):不作出判决,而是获取作出合法判决所需的具体、权威的先例和证据(外部数据)。
从技术上讲,它将参数记忆(存储在模型权重中的知识)与非参数记忆(无需重新训练即可更新的外部向量索引)结合起来。
如何将非结构化数据转化为知识?
任何RAG系统的有效性完全取决于其离线索引阶段的质量。这是为语义搜索准备原始数据的基础。
步骤1:信息提取与清洗
第一步是将非结构化数据源(例如PDF、图像或旧文档)转换为原始的、可处理的文本。此提取过程至关重要;如果文本提取过程中存在噪声,则下游嵌入的质量会降低。
步骤2:数据分块:为什么数据分块是一个关键超参数?
文本提取后,必须将其分割成更小的片段或“块”。选择合适的块大小(例如,128个词元还是512个词元)是一项至关重要的超参数调优工作。如果块太小,可能缺乏必要的上下文信息;如果块太大,则可能引入噪声,或者陷入“中间丢失”现象,即语言学习模型(LLM)无法处理隐藏在长上下文窗口中间的信息。
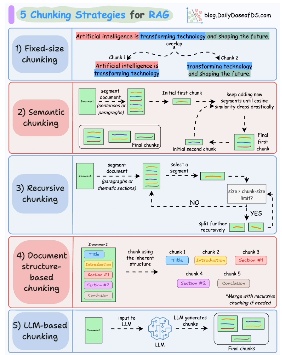
分块策略
步骤3:从稀疏嵌入到稠密嵌入
现代的RAG系统已经超越了TF-IDF或BM25等稀疏检索方法。相反,它们利用密集的、基于Transformer的词嵌入(例如BERT)来捕捉语义信息。这使得系统能够理解“猫科宠物”的查询与包含“猫”一词的文档在语义上相关,即使关键词并不重叠。
步骤4:元数据和上下文检索:结构化能否提高检索准确率?
简单地嵌入原始文本往往会导致上下文丢失。高级实现方案会使用元数据(例如时间戳或作者姓名)来丰富文本块。更复杂的方法,例如Anthropic的“上下文检索”,会在嵌入文本块之前对其进行预概括,使其包含整个文档的上下文。这确保了即使将单个段落与其相邻段落隔离开来,其含义仍然清晰易懂。
用户提交查询后会发生什么?
在线检索阶段决定了系统如何与实时用户意图进行交互。
查询优化如何提升搜索意图?
用户经常会编写含糊不清或模棱两可的查询语句。为了解决这个问题,工程师们采用了“重写-检索-读取”框架。这一步骤会将用户初始输入重新表述为更有效的搜索向量,确保检索系统搜索的是用户真正想要表达的内容,而不仅仅是他们输入的内容。
混合搜索的力量
纯粹依赖语义搜索可能会遗漏精确匹配项,例如零件编号。混合搜索通过结合以下方式解决这个问题:
1.密集向量:用于概念理解。
2.稀疏向量:用于精确的词汇/关键词匹配。
重新排序以提高精度
仅仅检索文档是不够的;系统必须对文档进行优先级排序。提炼和重排序涉及对检索到的文档进行过滤,以去除噪声,然后再将其传递给生成器,从而确保LLM的上下文窗口仅包含最相关的信息。
RAG背后的语义引擎由什么驱动?
这些系统的精度和速度由三个核心技术组件决定。
双编码器与交叉编码器
在数据摄取阶段使用嵌入模型(双向编码器)。它们将文档和查询映射到共享的向量空间,从而实现极快的相似性搜索(点积或余弦相似度)。
初始检索之后会采用重排序模型(交叉编码器)。与双向编码器不同,交叉编码器同时处理查询和文档。虽然它们的计算量更大、速度更慢,但它们在预测前k个结果与查询的相关性方面提供了更高的准确率。
向量数据库作为长期记忆
向量数据库充当应用程序的长期存储器。它不仅存储高维向量,还存储与这些向量关联的原始文本和元数据,即“有效载荷”。这使得系统能够在数学相似性搜索完成后,检索生成阶段所需的人类可读文本。
哪种RAG架构最适合你的使用场景?
随着人工智能应用需求的增长,简单的检索流程往往已无法满足需求。以下是目前人工智能工程师可用的八种不同架构。
- 简单RAG:使用现成的向量搜索的标准“检索-生成”流程。
- 带记忆功能的简单RAG:通过在上下文窗口中添加对话历史记录来增强基本模型,从而实现多轮对话功能。
- 分支RAG:利用分类步骤将查询路由到特定的数据源。例如,根据用户的意图,查询可能会被路由到特定的“法律”索引,而不是“技术”索引。
- HyDe(假设文档嵌入):这种架构会针对用户的查询生成一个假设的“理想”答案,嵌入生成的文本,然后搜索与该假设答案相似的真实文档。这显著提高了抽象查询的检索效率。
- 自适应RAG:一种动态系统,可根据查询的复杂性调整其检索策略,对于简单的请求,甚至可能完全跳过检索。
- 纠错型RAG(CRAG):此架构在生成结果之前评估检索到的文档的相关性。如果相关性得分低于阈值,则会触发回退机制(例如网络搜索)以查找更佳数据。
- 自我RAG:在此过程中,模型生成一个初始答案,对其进行评价,如果输出被认为不足或缺乏支持,则会启动一个新的检索周期来完善响应。
- 智能体RAG:这是最复杂的演进阶段,其中自主智能体协调整个检索过程。它们利用工具、规划和多步骤推理来回答需要综合多个不同步骤信息的复杂查询。
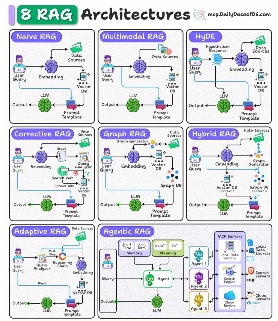
RAG架构
未来展望:RAG将走向何方?
如今,RAG正在从简单的查找演变为复杂的流程。主要趋势包括:
- 端到端训练:REALM和DPR等模型联合优化检索器和生成器。
- 多模态RAG:将文本、图像、音频和视频检索集成到单一工作流程中。
- 动态路由:诸如“自路由”之类的技术能够智能地决定何时检索外部数据,而不是依靠参数知识来平衡推理成本。
- 高级评估:超越相似性指标,实现“真实评估”,解决偏见和可扩展性问题。
总之,RAG已经发展成为一种复杂的、智能的工作流程,需要大量的内存带宽和先进的计算基础设施,例如NVIDIA GH200芯片。
你目前使用的是标准的“先检索后生成”流程,还是已经开始尝试使用代理RAG?
参考
- https://arxiv.org/pdf/2410.12837
- https://pub.towardsai.net/the-7-building-blogs-of-a-retrieval-augmented-generation-system-0a96ba82bb08
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:RAG Architectures: A Complete Guide for 2025,作者:Burak Degirmencioglu



