开源大型语言模型(LLM)领域正以惊人的速度演进,几乎每隔数月就有一款新模型问世,承诺具有更强的推理能力、更出色的编程能力以及更低的计算成本。
在众多竞争者中,Mistral公司始终是少数几家能持续兑现承诺的公司之一,而发布的Mistral 3系列更是将这一优势进一步扩大。此次发布并不是简单的更新迭代。
Mistral 3推出了一系列紧凑高效的开源模型,并同步推出了性能强大的Mistral Large 3模型。在本指南中,将详细解析Mistral 3的新特性,探讨其重要意义,并演示如何通过 Ollama安装与运行该模型,同时对其在实际推理和编程任务中的表现进行实测和分析。
Mistral 3概述:新特性与重要意义
Mistral 3于2025年12月2日发布,标志着开源人工智能领域向前迈出了重要一步。与一味追求更大模型不同,Mistral公司专注于提升效率、推理质量以及实际可用性。此次发布的这一系列模型阵容包括三款紧凑的密集型模型(30亿参数、80亿参数、140亿参数)和Mistral Large 3——这是一款稀疏混合专家模型(MoE)模型,在6750亿参数的架构中激活了410亿参数。
其模型套件均采用Apache 2.0许可证发布,这意味着它们可以完全用于商业项目,这也是开发者社区对此很感兴趣的主要原因之一。
Mistral 3的关键特性
·多种模型规格:Mistral 3提供基础版(30亿参数)、指令版(80亿参数)和推理版(140亿参数)三种变体,用户可以根据具体工任务(如聊天、工具调用、长文本推理等)灵活选择。
·开放且灵活:Mistral 3采用Apache 2.0许可证,使其成为目前最易获取、最适合商业应用的模型家族之一。
·多模态支持:所有模型均支持文本+图像输入,内置视觉编码器,使其可用于文档理解、图表分析和视觉任务。
·长上下文处理能力:Mistral Large 3可以处理多达25.6万个令牌,这意味着它可以一次性处理整体书籍、冗长的法律合同和庞大的代码库。
•更高的性价比:Mistral公司声称,其新的指令变体在性能上可媲美或超越其他开源模型,同时生成更多有效内容、减少冗余令牌,从而显著降低推理成本。
•推理能力提升:经过推理优化的140亿参数模型在AIME基准测试中取得了85%的得分——对于这一规模的模型而言,这是非常出色的成绩。
•边缘设备适配:30亿参数和80亿参数模型可以通过量化技术在笔记本电脑和消费级GPU上本地运行,而140亿参数模型则可轻松部署于高性能台式机或服务器。

使用Ollama搭建Mistral 3环境
Mistral 3的优点之一是能够在本地机器上运行。Ollama是一款免费工具,可以作为命令行界面,在Linux、macOS和Windows系统上运行大型语言模型(LLM)。它可自动处理模型下载并提供GPU支持。
步骤1:安装Ollama
运行官方脚本安装Ollama二进制文件和服务,然后使用Ollama——version(例如,“Ollama版本0.3.0”)进行验证。
curl -fsSL https://ollama.com/install.sh | sh
•macOS用户:从ollama.com下载Ollama DMG并将其拖动到应用程序。Ollama将自动安装所有所需依赖项(包括针对基于ARM的Mac的Rosetta)。
•Windows用户:从Ollama GitHub存储库下载最新的.exe文件。在安装后,打开PowerShell并运行ollama serve。守护进程将自动启动。
步骤2:启动Ollama
启动Ollama服务(通常自动完成):
ollama serve
现在,可通过以下地址访问本地API:http://localhost:11434
步骤3:下载Mistral 3模型
下载量化后的80亿参数指令模型:
ollama pull Mistral:8b- instruct_q4_0
步骤4:交互式运行模型
1ollama run Mistral:8b-instruct-q4_0
这将打开一个交互式REPL。输入任何提示符,例如:
> Explain quantum entanglement in simple terms.
模型将立即响应,用户可以继续与它交互。
步骤5:使用Ollama API
Ollama还提供了一个REST API。以下是一个用于代码生成的示例cURL请求:
curl http://localhost:11434/api/generate -d '{
"model": "Mistral :8b-instruct-q4_0",
"prompt": "Write a Python function to sort a list.",
"stream": false
}'
Mistral 3的能力
Mistral 3是一个通用模型套件,可用于聊天、问答、推理、代码生成与分析以及视觉输入处理。其内置的视觉编码器可以对给定图像生成描述性回应。为了展示Mistral 3模型的能力,使用Ollama对其进行了三组逻辑推理和编程问题的测试:
- 逻辑谜题测试推理能力
- 代码文档生成与理解
- 通过多进程实现测试编程技能
为此,使用Ollama查询Mistral 3模型,并观察其表现。以下将简要讨论任务内容、性能结果和基准测试情况。
任务1:逻辑谜题测试推理能力
提示:
四位朋友:在A、B、C、D四人当中,有人被怀疑私藏了一把钥匙,而每人都各自声明:
A:“钥匙在B那里。”
B:“钥匙不在C那里。”
C:“钥匙在D那里。”
D:“钥匙不在我这里。”
这四句话中只有一句是真话,那么谁私藏了钥匙?
Mistral 80亿参数模型响应:

该模型花费数秒时间评估并分析了所有可能场景,最终在约50秒内给出了正确答案:C。

本文观点:
这个模型准确地解开了谜题,并采用了逐步推理的分析方法。通过逐一排查各种可能情形,最终得出结论,确定C私藏钥匙。不过,在响应时间上出现了较为明显的延迟:80亿参数版本耗时约40至50秒才得出结果。这一延迟很可能由于本地硬件性能的限制,而非模型本身的推理效率问题。
任务2:代码文档生成与理解
提示:
请根据代码文件提供完整文档。文档应包含:
1) 文档字符串
2) 注释
3) 函数的详细说明
Mistral 3的回应:







本文观点:
模型输出的文档虽然可用,但未能完全符合指令要求。文档字符串、内联注释和函数级别的详细说明等关键要素或者完整,或者完全缺失。尽管模型理解了任务要求,但未能以全面、适合开发者的格式组织文档。
任务3:通过多进程实现测试编程技能
提示:
编写一个使用多进程模块并行计算前N个自然数平方和的Python程序。
将数字范围划分为更小的块,让每个进程计算其块的平方和部分,最后合并部分结果得到总和。 然后,比较多进程实现与单进程版本的性能。 Mistral 3的响应:
python
import multiprocessing
import time
import math
def sum_of_squares_single(n):
"""Compute the sum of squares of the first N natural numbers in a single process."""
return sum(i ** 2 for i in range(1, n + 1))
def sum_of_squares_parallel(n, num_processes=None):
"""Compute the sum of squares in parallel using multiprocessing."""
if num_processes is None:
num_processes = multiprocessing.cpu_count()
chunk_size = n // num_processes
chunks = [(i * chunk_size + 1, (i + 1) * chunk_size) for i in range(num_processes)]
def compute_chunk(start, end):
return sum(i ** 2 for i in range(start, end + 1))
with multiprocessing.Pool(processes=num_processes) as pool:
partial_sums = pool.map(lambda args: compute_chunk(*args), chunks)
return sum(partial_sums)
def compare_performance(n):
"""Compare single-process and parallel performance."""
print(f"Computing sum of squares for the first {n} natural numbers...")
# Single-process
start_time = time.time()
single_result = sum_of_squares_single(n)
single_time = time.time() - start_time
print(f"Single-process time: {single_time:.6f} seconds")
print(f"Single-process result: {single_result}")
# Parallel
start_time = time.time()
parallel_result = sum_of_squares_parallel(n)
parallel_time = time.time() - start_time
print(f"Parallel time: {parallel_time:.6f} seconds")
print(f"Parallel result: {parallel_result}")
print(f"\nSpeedup: {single_time / parallel_time:.2f}x")
if __name__ == "__main__":
N = 10**6 # Example: Compute for first 1,000,000 numbers
compare_performance(N)
终端响应:

本文观点:
模型的代码生成能力很强。它生成了一个模块化、清晰且功能完备的多进程解决方案。它正确实现了分块逻辑、进程池、部分和计算以及清晰的性能比较。然而,与任务2类似,其生成的代码缺乏适当的注释和文档字符串。虽然逻辑准确且完全可运行,但解释性注释的缺失降低了代码的整体清晰度和对开发者的友好度。
基准测试与观察结果
Mistral 3的整体性能表现出色。以下是模型运行时的关键基准测试结果和发现:
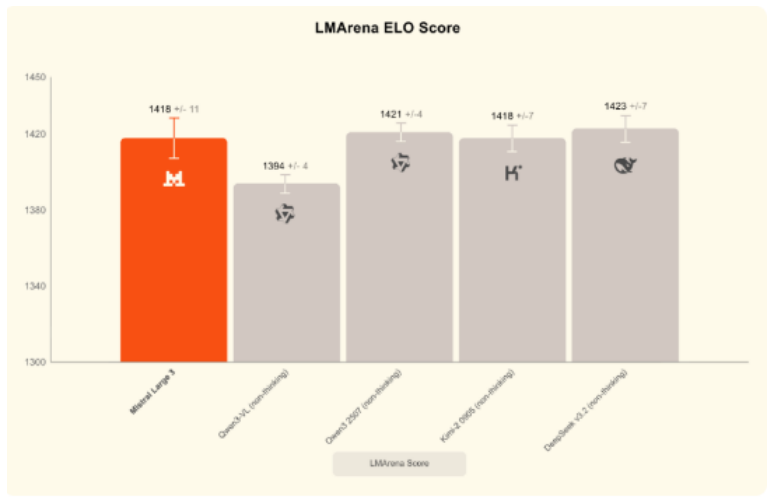
开源领域的佼佼者
作为一款开源模型,Mistral Large在推理能力上表现突出,在LMArena排行榜上取得了很高的排名(在开源模型类别中排名第二,总排名第六)。它在两个热门的基准测试MMMU(综合知识)和MBB(推理)上也取得了相同或更好的排名,超过了几个领先的闭源模型。

数学与推理基准测试
除数学基准测试外,Mistral 140亿参数模型在AIME25(0.85 vs 0.737)和GPQA Diamond(0.712 vs 0.663)上的得分均高于Qwen-14B。AIME25用于衡量数学能力(基于MATH数据集),其他基准测试则用于衡量推理任务。MATH基准测试结果显示:Mistral 140亿参数模型得分约为90.4%,而谷歌120亿参数模型得分为85.4%。

编程基准测试
在HumanEval基准测试中,发现专门针对代码的Codestral模型非常有效,在测试中得分为86.6%。此外还注意到,Mistral对大多数测试问题生成了准确的解决方案,但由于其平衡的设计,在某些挑战性排行榜上略低于规模最大的编程模型。
效率(速度与令牌生成)
Mistral 3运行效率很高。最近的研究表明,其80亿参数模型在现代GPU上的推理速度约为50~60个令牌/秒。紧凑型模型的内存占用也更低:例如,30亿参数模型在磁盘上仅占用数GB空间,80亿参数模型约占用5GB,140亿参数模型约占用9GB(非量化版本)。
硬件规格
验证发现,16GB GPU足以流畅运行Mistral 30亿参数模型。运行Mistral 80亿参数模型通常需要约32GB内存和8GB GPU内存;不过,它可以通过4位量化在6~8GB GPU上运行。Mistral 140亿参数模型的多个实例通常需要顶级或旗舰级GPU(例如24GB显存)或多块GPU。小型模型的CPU版本可使用量化推理运行,但GPU仍然是速度最快的选择。
结论
Mistral 3是一款快速、强大且易于获取的开源模型,在推理、编程和现实世界任务中均表现出色。其小型变体可以轻松地在本地运行,而其大型模型则以更低的成本提供了具有竞争力的准确率。对于开发人员、研究人员还是人工智能爱好者来说,不妨尝试使用Mistral 3,看看它如何融入自己的工作流程。
原文标题:Mistral Large 3: First Look and Testing,作者:Vipin Vashisth
